Video annotation enhances computer vision models by accurately labeling visual data for various applications, including autonomous vehicles, human movement analysis, and medical imaging diagnostics. Best practices in annotation ensure model accuracy, efficiency, and bias prevention.
Video annotation involves adding metadata to specific frames or objects within a video for training and evaluating computer vision models. This enables the models to accurately recognize and interpret visual content within videos.
Video annotation use cases can be found across various industries that use computer vision models for task automation and scrutiny. In autonomous vehicles, video annotation helps train models recognize objects and predict their trajectories. In healthcare, it aids in disease diagnosis through the analysis of medical imaging videos. In surveillance, it enables real-time threat detection.
The global computer vision market is projected to grow annually at (CAGR) 10.50% from 2024 to 2030. This translates to an estimated market volume of US$46.96 billion by 2030.
However, inaccurate annotation introduces bias into models. It hinders their performance and negatively impacts real-world applications. By labeling video for computer vision accurately, you empower your models to recognize and interpret visual data, thus improving their efficiency.
Here, we take a look at how this translates to success through three major use cases.
How high-quality video annotation helps optimize computer vision models
High-quality video annotation plays a crucial role in refining and optimizing computer vision models and improving their performance across several key dimensions.
The following illustrate the importance of video annotation in computer vision:
1. Model accuracy and bias prevention
Precise object boundaries and key point annotations across video frames allow models to understand and track objects more accurately, even when challenged by occlusions or lighting changes.
Ensuring diversity and balance in annotated video data minimizes the risk of bias and promotes fairness in computer vision applications. This involves considering factors such as demographics, representation of different groups and potential sources of bias during the video annotation process.
2. Accelerated model training and development
Detailed and well-structured annotations in multi-class or complex object scenarios guide models towards faster convergence, shortening the training cycle.
By providing clear and consistent training signals, high-quality annotations speed up the iterative process of model refinement and optimization, allowing faster deployment.
3. Better generalization to unseen data and real-world conditions
Annotating a diverse range of videos that encompass various scenarios, viewpoints and environmental conditions enables models to learn robust representations that can generalize well to unseen data and real-world conditions.
This ability proves crucial for applications where models must function in dynamic, unpredictable environments, like autonomous driving or security surveillance.
Use Case 1: Video annotation aids navigation in autonomous vehicles

In making autonomous vehicles safer and more reliable, video annotation plays a crucial role in enhancing navigation capabilities.
A. Object detection and tracking
In autonomous vehicles, bounding boxes provide precise locations and sizes for objects of interest within each video frame. The accuracy of these bounding boxes labeling videos is crucial for training these object detection models.
These models must identify pedestrians, other vehicles, cyclists and obstacles in real time. By assigning semantic labels like “car,” “pedestrian,” or “traffic light,” we equip the autonomous vehicle’s perception system to classify and comprehend the nature of its surroundings.
This classification, in combination with robust tracking algorithms, empowers the vehicle to anticipate the movement and interaction of objects along its path. This understanding directly informs critical decision-making processes for path planning and collision avoidance.
Video annotation also facilitates the continuous and accurate tracking of objects over time. This provides the vehicle with a dynamic understanding of its environment, which is essential for safe and reliable autonomous navigation.
B. Lane detection and road segmentation
Annotating lane markings, road boundaries and drivable areas is crucial for an autonomous vehicle to understand the road layout. Semantic segmentation, a pixel-level classification technique, helps in this process.
By training on accurately annotated video data, where each pixel is labeled with its corresponding class (e.g., lane marking, road, sidewalk), the autonomous vehicle learns to perceive the road structure. This understanding is fundamental for accurate path planning, ensuring the vehicle stays within its lane and avoids collisions.
C. Traffic light and sign recognition
Recognizing and interpreting traffic lights and signs is critical for autonomous vehicles to adhere to traffic regulations. This task presents a significant challenge due to varying lighting conditions, occlusions and the diversity of traffic sign designs across geographies.
Annotated video data, where traffic lights and signs are accurately labeled with their corresponding states (e.g., red, green, stop, yield), allow training of robust computer vision models. These models, leveraging deep learning techniques, accurately perceive and interpret traffic signals in real-world driving scenarios.
D. Behavior prediction and anomaly detection
Predicting pedestrian and driver behavior is essential for anticipating potential hazards and ensuring safe navigation. Annotated video data capturing a wide range of traffic situations and behaviors can train models for behavior prediction.
Annotating the attributes of objects (e.g., vehicle type, pedestrian age) or the environment (e.g., weather) is useful in building accurate prediction models.
Annotated video data helps these models to learn actions such as pedestrians crossing the road or vehicles changing lanes, enabling autonomous vehicles to take preemptive measures.
By training on datasets that include annotated anomalies (e.g., sudden braking and erratic driving), autonomous vehicles learn to identify and respond to these situations effectively.
Video Annotation for Data Analytics Company

Hitech BPO efficiently annotated millions of live traffic video frames for a data analytics company, supporting improved road planning and traffic management. We categorized vehicle and pedestrian movements across various conditions to create training datasets for machine learning models, enabling accurate traffic analysis and accident prevention.
Read full case study →
Enhance your AI models with accurate object detection and tracking services.
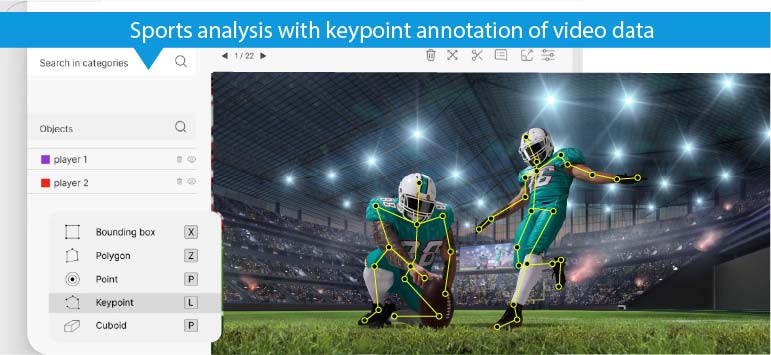
Use Case 2: Video annotation in pose estimation and action recognition understands human movement

Video annotation serves as the foundation for training computer vision models to accurately estimate human poses and recognize actions in videos. This enables a deeper understanding of human movement, with a wide range of applications in various domains.
A. Human pose estimation
Using keypoint annotation on the human body in video frames, we provide models with the ground truth needed to learn the spatial relationships between body parts and their movements over time. This granular level of annotation enables both 2D and 3D pose estimations.
Video annotation examples for 2D pose estimation include datasets like MPII Human Pose Dataset and COCO, which focus on locating and connecting keypoints (e.g., joints, limbs) on a 2D image plane. These algorithms are applied in the development of more intuitive computer interfaces that respond seamlessly to human body language.
3D pose estimation demands larger datasets with diverse viewpoints and often utilizes multi-view setups. 3D human pose estimation is key to achieving lifelike character movements in motion capture for animation and gaming. It is also used in gait analysis to identify movement disorders.
B. Action recognition in sports and beyond
Video annotation for action recognition focuses on labeling video segments with specific actions or activities. This involves both temporal segmentation to define the action boundaries and categorical labeling to identify the type of action.
In sports like soccer, basketball, and tennis, action recognition models help automatically track player movements, identify specific actions (e.g., shots, passes, tackles), and extract performance metrics. This data is used for player evaluation and scouting and helps in real-time game analysis and strategic decision-making.
Action recognition also plays a vital role in automated surveillance systems. By recognizing suspicious activities (e.g. loitering, fighting, intrusions), these systems help improve security in public spaces and trigger alerts for timely intervention.
C. Gesture recognition and sign language interpretation
Gesture recognition relies heavily on video annotation to capture the nuances of hand and body movements. Annotating hand gestures, such as pointing, waving or specific hand shapes, enables the training of models for controlling devices with gesture-based interfaces.
It also helps in understanding non-verbal communication cues such as gestures and facial expressions in psychology, marketing and human-computer interaction.
Accurate sign language recognition requires extensive video annotation of handshapes, facial expressions and body movements. Datasets like the American Sign Language Lexicon Video Dataset and iSign are crucial resources for training models to translate sign language into text or speech.
Computer vision models trained on such video datasets facilitate real-time translation of sign language videos.
Improve object localization in videos with our precise bounding box annotations.
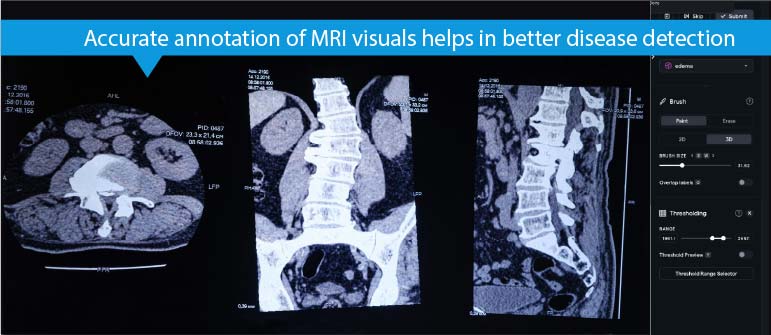
Use Case 3: Video annotation in medical imaging aids advanced diagnostics and treatment

Video annotation makes medical videos more useful and informative. This helps drive advancements in diagnostics and treatment and leads to better patient outcomes.
A. Medical image segmentation for disease detection and classification
Accurate segmentation of organs, tumors and other structures in medical visuals like MRIs, CT scans, and X-rays is crucial for diagnosis, treatment planning, and disease monitoring. Manual segmentation is time consuming and prone to inter- and intra-observer variability.
Annotated medical frames are fundamental in training computer vision models for detecting and classifying diseases, leading to early detection and improved diagnostic accuracy.
Annotated videos provide the ground truth for supervised learning algorithms. Each frame is labeled with the presence or absence of specific pathologies, such as cancerous lesions or Alzheimer’s-related plaques.
Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are particularly adept at extracting spatiotemporal features from medical image sequences, enabling the identification of subtle patterns indicative of disease.
B. Surgical planning and robot-assisted surgery
Video annotation for computer vision is transforming surgical practices by enabling accurate pre-operative simulations and enhancing the precision of robot-assisted procedures.
Annotated videos of previous surgeries provide a rich dataset for training simulators. Surgeons can rehearse complex procedures and familiarize themselves with anatomical variations and potential complications in a risk-free environment.
By comparing the live surgical video feed with pre-annotated data, computer vision models assist in precise instrument manipulation and tissue identification. This level of precision facilitates the adoption of minimally invasive surgical techniques, leading to faster recovery times and reduced patient discomfort.
C. Drug discovery and personalized medicine
The analysis of cellular behavior and drug responses using annotated video data is accelerating drug discovery and paving the way for personalized medicine.
Automated analysis of cell morphology, movement, and interactions with potential drug candidates, as captured in time-lapse microscopy videos, allows for rapid screening of vast chemical libraries.
Associating annotations (object labels, events) with specific time points or intervals within the video enables tracking of changes in cell behavior or drug effects over time. Analyzing such video data from individual patients helps identify unique disease characteristics and predict treatment responses, enabling the development of tailored therapeutic approaches.
Best practices of video annotation for training computer vision models
To fully leverage video annotation, it is crucial to implement best practices that optimize both model training and its performance.
- Maintain temporal consistency: Consistent object labels and attributes across frames ensure the model understands continuity and coherence, which is especially important for tasks like object tracking and action recognition.
- Utilize interpolation and keyframe labeling: Strategically annotating keyframes that capture critical moments in the video and then using interpolation to fill in the gaps optimizes labeling efficiency without sacrificing accuracy.
- Implement multi-class labeling: Assigning multiple labels to an object based on its various attributes or roles within a scene deepens the model’s understanding of the visual context.
- Handle occlusions effectively: Accurate annotation of even partially obscured objects builds robustness into the model, allowing it to recognize and track objects in real-world scenarios where occlusions are common.
- Employ multiple annotation and consensus: Having multiple annotators independently label the same video segments and using consensus mechanisms to resolve disagreements improves annotation accuracy and minimizes bias.
- Conduct regular audits and reviews: Periodically reviewing and auditing annotations helps identify and correct errors, ensuring the integrity of the training data and, consequently, the model’s performance.
- Match annotation granularity to the task: Tailor the level of detail in your annotations to the specific requirements of the model and the task at hand. For example, object detection might require only bounding boxes, while action recognition might necessitate more intricate annotations.
- Leverage data augmentation: Strategic augmentation of the annotated dataset with transformations like cropping, rotation and flipping increases the model’s resilience to variations in visual input.
Incorporating these best practices into your video annotation process will significantly improve the quality of your training data, leading to more accurate, reliable and effective computer vision models.
Moving forward
Accurate video annotation provides high quality labeled training data that your computer vision models need to understand and interpret visual information, enabling a broad spectrum of innovative applications across various sectors.
The increasing use of computer vision applications across various industries is fueling a surge in demand for high-quality annotated video data. This rising demand will spur innovation in annotation tools and techniques. We can anticipate advancements in areas, such as weakly supervised and unsupervised learning in AI video annotation.
These advancements will streamline your video annotation process, making it accurate, efficient and more cost effective.
By adhering to best practices and utilizing the appropriate tools and techniques, you enhance the quality and efficiency of your annotation process. This ultimately leads to accurate, reliable and impactful models that help realize the full potential of your computer vision projects.