
5 Powerful Ways Image Annotation Improves Computer Vision
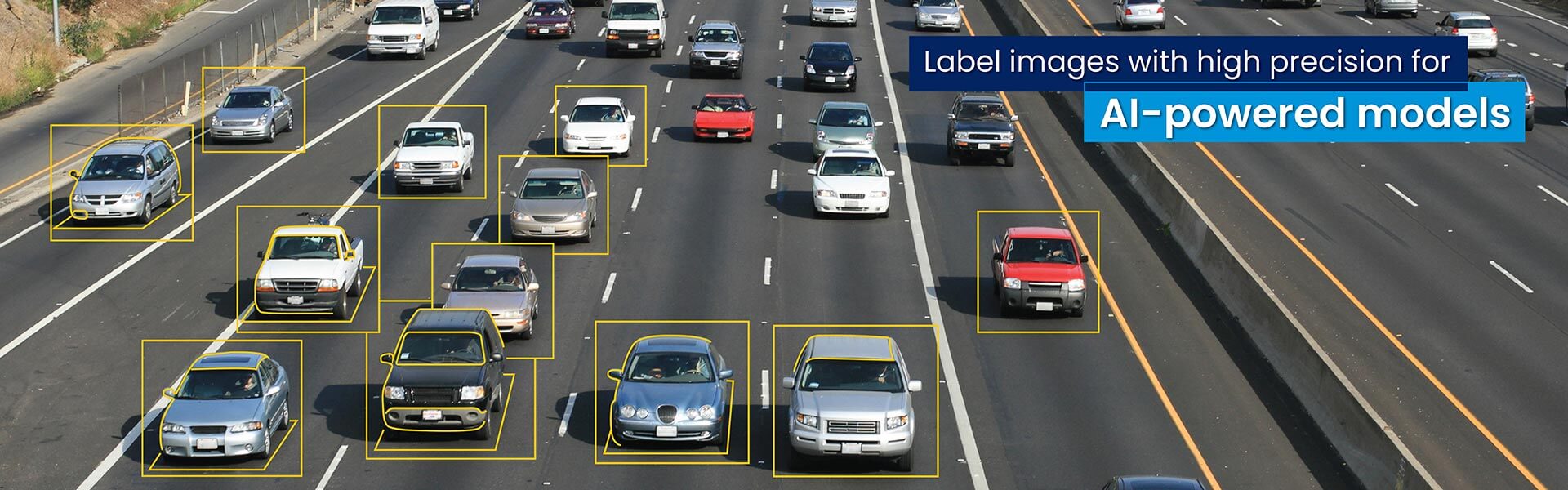
To create a properly representative and high-quality training dataset, any image labeling for AI powered computer vision models involves a series of steps. These include preprocessing and augmentation, data splitting for quality checks and test runs, iterative refinement, and more.
Table of Contents
In order to “see” and understand the world, computer vision models need to be trained on massive amounts of visual data. However, this data needs to be accurately annotated and categorized so the AI model can understand what it represents.
In image labeling for AI training, annotators provide the essential structure that enables AI models to learn what’s within the picture by carefully adding descriptive tags (labels) to images. This is the core of all work done for any machine learning image annotation.
However, despite the availability of automated labeling systems, for AI training data labeling, human supervision and quality control remains necessary, especially in sensitive cases like medical image analytics.
In this article we walk you through the various phases involved in image labeling for computer vision models. We will also discuss image labeling techniques and tools.
The best ways to label images for AI adopt a blend of three distinct approaches: manual, semi-automated, and synthetic.
While techniques like image classification, object detection, and semantic segmentation form the basis of image annotation, high-quality image labeling also requires preprocessing of images, data augmentation, and quality checks.
Before starting to label the images, you will have to optimize the images and make them easier for the model to learn from.
To begin the image labeling process for preparing training data, first we need to optimize the images to create primary image datasets fit to label.
Common processing techniques include resizing and cropping, normalization, color space conversion, noise reduction and contrast enhancement.
To help the model learn from a wider range of examples, you need data augmentation, which involves creating new image data from existing ones. The augmented images are labeled in the same way as the original images to increase the diversity and size of the labeled dataset.
These techniques standardize image data, making it easier to conduct precise labeling for more accurate and efficient AI models.

Even the best machine learning algorithms produce unreliable results if trained on poorly labeled data.
To achieve AI model accuracy, you have to ensure the highest quality of image labels. You do this through clear labeling guidelines, splitting data for training, validation, and testing, using quality control metrics, and refining image datasets through iterations.
After labeling a dataset, you divide it into three distinct sets for training, validation, and testing. This split helps ensure the model responds well to unseen data and avoids overfitting.
Here’s a breakdown of the common data splits and their purposes:
By evaluating the model’s performance on the validation set, we you can identify potential overfitting and adjust hyperparameters to improve generalization.
For high quality image labelling, we need to prioritize annotation quality and use quality control metrics. For this, we ensure tight bounding boxes with high Intersection over Union (IoU) for accurate object localization. We aim for high precision to minimize false positives and high recall to catch all relevant objects.
To ensure consistent image data labeling, we use Inter-Annotator Agreement (IAA) metrics like Cohen’s Kappa (two labelers), Fleiss’ Kappa (more than two), or Krippendorff’s Alpha (versatile) to measure how much we agree on our annotations. This helps us identify and fix inconsistencies, leading to better model training and performance evaluation.
You begin with a smaller, well-defined set of images representing the core concepts. This allows you to quickly spot weaknesses in the initial labeling. This is repeated and as the model improves, you gradually expand the dataset’s complexity and diversity.
You target specific inadequacies in labeling, or the dataset directly based on the model behavior in real time. Using the insights to collect new images that specifically target the weaknesses identified by the model, you retrain the model on the updated and expanded image dataset.
You also use insights from model errors to inform data augmentation techniques (e.g., rotating, blurring, or adding noise to images). This helps the model become more resilient to variations it might encounter in real-world applications.
Consider developing an image classifier to detect and distinguish between different types of road signs (speed limit, stop, yield, etc.).
The following loop is followed for image labeling in ML:
By continuously closing this loop, the image classifier becomes more efficient making its perception system more reliable.
It is important to select the right image labeling technique that aligns with your project’s goals for successful machine learning outcomes. Factors like image complexity, desired output, and model type have to be considered.
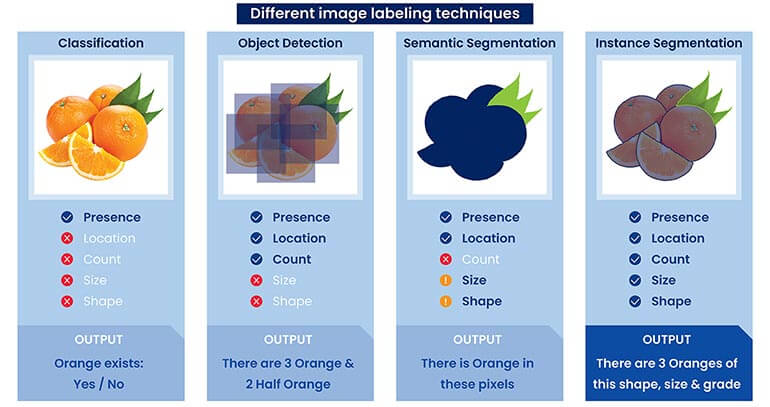
Here’s a breakdown of the primary image labeling techniques used for creating AI training data:
This involves assigning a single label to an entire image based on its dominant content. For example, a picture of a dog might be classified as “dog” or a landscape photo as “mountains.”
Applications: Organizing personal photo libraries, automatic sorting of product images for e-commerce, initial screening of medical images for broad categories.
Object detection involves identifying and localizing multiple objects of interest within a single image. This requires drawing bounding boxes or polygons around each detected object and assigning it a corresponding label.
For example, multiple objects like “cars,” “pedestrians,” and “traffic lights” can be identified and labeled within a street scene image.
Applications: Self-driving cars (identifying obstacles, pedestrians, traffic signals and other vehicles), robotics (picking and placing objects), inventory management (counting and locating items on shelves), manufacturing (spotting defects on assembly lines).
It involves labeling every pixel in an image with its corresponding class. This provides highly detailed, pixel-level precision while labeling.
For instance, outlining precise boundaries of roads, buildings, cars, vegetation, etc., in a satellite image.
Applications: Autonomous vehicles (understanding the exact layout of the environment), medical imaging (detecting the shape and size of tumors or other anomalies), land-use analysis in satellite imagery
Though similar to semantic segmentation, instance segmentation goes a step further by differentiating between individual instances of the same class.
For example, in an image from a busy street, this outlines cars with pixel-level precision also labeling each instance of the ‘car’ class separately, i.e., “car 1,” “car 2,” etc.
Applications: Crowd counting and tracking, precise object tracking in videos, medical applications where analyzing individual organs or cells is crucial
While labeling images you use one or more types of image annotation as listed below:


Hitech BPO achieved 100% accuracy in annotating image datasets of kitchen waste to train a Swiss company’s food waste assessment models. This involved image segmentation, annotation, auditing, and iterative review. Rigorous training and validation ensured recognition of diverse European food items. By automating data feeding, the client’s models gained real-time insights into food waste metrics.
Read full case study »When choosing an image labeling tool for AI training data, you need to consider several key factors. These include:
By carefully considering these factors and adhering to image labelling best practices, you can select an image labeling tool that helps to create high-quality AI training data efficiently, ultimately leading to better-performing machine learning models.
Roboflow Annotate, Labelbox, Scale AI, SuperAnnotate, and Dataloop are a few among the top image annotation tools available today.
To accurately label images for AI-powered models, you need to follow best practices, such as creating clear and concise annotation guidelines, training annotators thoroughly on project specifications, and incorporating review and consensus stages in the annotation workflow. It is important to remember that the quality of input data directly influences the performance of the AI model.
Moving toward a future where AI-powered communication becomes the norm, the reliability and performance of computer vision models will assume center stage in our everyday life, and the demand for accurately labeled image data will keep growing. Therefore, investing time and resources in proper image labeling and tie-ups with reliable image labeling services will hold the key to success in AI projects, now and in the foreseeable future.

What’s next? Message us a brief description of your project.
Our experts will review and get back to you within one business day with free consultation for successful implementation.
Disclaimer:
HitechDigital Solutions LLP and Hitech BPO will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@hitechbpo.com



Leave a Reply